归因是个有意思的问题,许多领域都在研究,比如心理学中就有“基本归因错误”(Fundamental Attribution Error,FAE);而广告和金融领域更是对归因进行了深入研究,来辅助广告主和投资人获得更大的收益,避免损失。


一、归因问题
在前一篇《数据产品经理:6大数据分析平台的“世界观”》中主要讲解了6个数据分析平台的数据模型,这6个平台都是大家耳熟能详的,特别是对于中小型企业和团队,在保证数据分析效果的同时,能有力的减少创业初期阶段在数据上的成本投入。
但在结尾的地方,我们留下了一个没有展开的问题——归因。
事情是这样发生的:
我们使用了LinkedIn经典的“魔法数字”案例,也就是“1周内增加5个社交好友的用户更容易留存”。
但是这个结论是如何的出来的呢?
1周内可能发生很多事情,比如用户年龄段的改变、地理位置的改变、偏好的改变等等,我们是如何将最终的留存率“归功于”社交好友数量的呢?而且这5位社交好友是否同等重要呢?
这就是归因问题。
归因的正面作用,它可能是全部数据分析要解决的唯一问题——解释“为什么”,但反面作用,归因不当将会摧毁整个分析的可信度。而且,很可能我们从原始数据的收集和整理方法中,就已经定下了一个大败局——终将“溃于蚁穴”。
为了解决这样的问题,在数据平台上通常会提供几种归因的方案供客户选择:
1. 首次互动归因模型
也就是用户第一次做某件事,在数据中通常表现为时间最早、顺序号最小等等。当然,这是理想情况。在现实中由于种种原因,我们无法从用户的最终转化一直向前追溯,直至真实的“首次互动”。遇到这种情况,也就只好采用能追溯到的、并且与业务相关的首次行为了。
比如:在用户的一次购买转化中,我们可以用订单号追踪;没有订单号,可以用账号;账号没有,可以用访问会话(Session ID);会话没有,可以用设备ID;如果实在是什么都没有了,那么用户以前的行为,我们只好当它不存在。
2. 最终互动归因模型
也就是用户最后一次做某件事,对应的在数据中就表现为时间最近、顺序号最大等等。同样,在最终互动中也存在“数据问题”——直接访问流量(Direct Traffic),也就是那些找不到前置行为却完成了转化的流量。为了排除它们的干扰,有时也采用最终非直接互动归因。
3. 线性归因模型
也就是平均分。比如前面的LinkedIn的例子,如果用户添加了5个社交好友并留存下来,那么前面的5个社交好友“同等重要”,全都是促成最终结果的重要因素。
4. 加权归因模型
也就是给多个促成因素分配一定的权重。
比如:如果用户从某商城中看了许多商品才下单,在订单页点击了提交按钮,在支付页点击了支付按钮,在订单完成页点击了查看订单详情按钮。一套动作下来,这笔订单应当归功于那个按钮呢?
显然在随意浏览的过程中,点击行为没有那么重要。相比之下,后边的三个按钮就重要得多。
那么怎么定权重呢?前面的线性相当于等权,还有时间衰减模型、U型/W型/Z型模型。这方面文章很多,不再展开。
以上几种方法是比较简单易懂的,而且可以想象计算量与计算复杂度都不大。但是对于归因这么重要的一件事,只有这些简单粗暴的办法么?
当然不是。
比如下面这个:
5. 马尔科夫归因
这是把用户的转化行为比作“马尔科夫链”,来计算各个状态之间的转化概率。简单来说,就是“明天只与今天有关,而与昨天无关”。这样,我们也就可以计算出用户转化路径中的各个步骤之间的概率,并最终算出权重。如果我们用这个权重来代入前面的加权归因,是不是瞬间感觉高大上了么?(如果对概率论还有印象的同学,可能会想起一个十分类似的东西——贝叶斯公式。)
二、归因模型的选择
Well,不知道各位小伙伴是什么感觉,反正我每次看到这种“N种方法”的状况是很头疼的,究竟怎么选呢?
这是个问题。
我们曾介绍:GrowingIO只提供了两种归因模型——首次和最后(在手册中“埋点事件”的“归因方式”一节,参考:https://docs.growingio.com/docs/),而Google Analytics for Firebase则提供了归因模型。
至于其他没有“明说”的平台,为了节(lan)省(ai)时(wan)间(qi),我是没有验证。
这样看,似乎不同的平台都有自己在模型上的取舍。那是否存在一套通用的模型呢?为什么我们不直接采用看上去就很高大上的马尔科夫链,而还是要用最简单粗暴的归因方式呢?
这里主要考量两个因素:
1. 业务形态
说是业务形态,但其实是个比较抽象的概念。落实到数据上,就是我们究竟能拿到什么样的数据。(数据内容是《数据产品经理:6大数据分析平台的“世界观”》这篇的主题,有兴趣的同学可以翻回去看看)。
第三方平台通常以行为分析为重,但与业务相关的数据就不那么容易拿到了,比如商品ID、交易金额、支付渠道等等。
因此:即使我们把事件模型收集到的数据拼成一个长长的链条,但是除了直接导致最终转化的这个环节以外,前面的环节很可能根本没有上报业务相关的数据,或者上报的信息不完整、不准确。所以我们可以轻松地追踪行为,却不太容易从促成转化的角度追踪所有相关的行为,除非详细地配置了各种自定义事件。
因此,除非在业务形态(产品形态)上以用户行为为主(比如短视频类的浏览、点赞、收藏、转发),否则只好在归因方面采用相对简单的归因方法。
而企业内部的数据则更加贴近自己的核心业务,可以方便的拿到核心业务数据。这就适合业务形态(产品形态)比较复杂的情况了。我们也可以相对容易地追踪到促成转化的整个流程。比如电商中的“逛”就是个挺难分析的过程,还有金融中的投资行为等等。它们都需要与业务数据深度结合进行分析,也适合使用相对复杂的归因模型。比如用来分析投资组合的Brinson模型。
2. 计算量
第二个要考虑的因素就是计算量。计算量主要来源于两个方面:数据量与计算复杂度。
数据量比较好理解,典型的数据量爆发场景,就是每每有企业自豪地宣布日活数据、留存数据、交易额/交易人数等数字的时候。这些数字的背后,都是浩如烟海的数据内容。
那么什么叫计算复杂度?这个概念可繁可简。比如,我们拿到的数据是3和10两个数字,你来体会一下心算“3×10”与“3的10次方”之间的区别吧,大概就是这个感觉。
三、归因的延伸
前面讲到的基本都是归因模型的直接应用,也就是“给转化找原因”。
但是既然我们说了归因是分析的全部目的也不为过,那么归因模型也应该有一些延伸应用。比如看看下面这个问题:
既然归因是给转化找原因,而说到转化大家一定会想起漏斗模型,那么归因与漏斗之间是什么关系?还有前面提到的转化路径,难道不是漏斗么?嗯……我已经表达过对于N多模型的厌恶之情,所以这几个之间的关系一定要弄明白。
我们从各种数据采集中得到的信息是很有限的,它们不会超过我们预先能想到要看的那些指标,包括页面上元素的曝光、点击、滑动等基本行为,以及与业务相关的发布内容、拍摄视频、点赞、收藏、下订单、完成支付等等行为。即使是“无埋点”方案,能够采集到的内容也是预先设计好的,并且是更基础、更通用的指标。
很显然,这些基本的指标决不能跟“用户行为”划等号,充其量是用户行为的子集,并且是很小的一个子集。这其中有技术问题,有认知问题,有各种各样的问题。那么用户行为到底是什么样的呢?
其实这个问题不重要,重要的是,我们究竟关心哪些行为。这就是漏斗。
在当今的分析中,大多数人会采使用转化漏斗,来描绘一个对于业务或产品来说最关键的路径。用户在这个路径上如何流动,决定了业务或产品是否存在问题、是否还有发展空间。而这个转化漏斗背后,则是一个价值产生的过程(消费、投资、……),或者是用户的一个心理过程(学习、表达、……)。
所以虽然都是行为,漏斗与行为轨迹的出发点就是不同的——漏斗是业务或产品的角度,行为轨迹是用户的角度。两个往一起一碰,这就有意思了——我希望用户赶快买,但是用户就是转转悠悠的不下单。TA在干什么呢?拼出来一个行为路径看看TA到底在干什么。
总结起来,漏斗是从业务或产品自身的形态出发,在所有用户可能产生的行为路径中,寻找出真正重要的节点;而归因则是将漏斗进行横向拆解,研究促成每一个节点的真正原因是什么,以及如何加强。
比如下面这张图,绿色圆圈才是我们的转化漏斗,与蓝色箭头则找出了每一段的“直接因素”。当然,这画的是理想情况。如果我们的产品设计出现问题了,则会看到越来越多的用户经过了其他的路径。
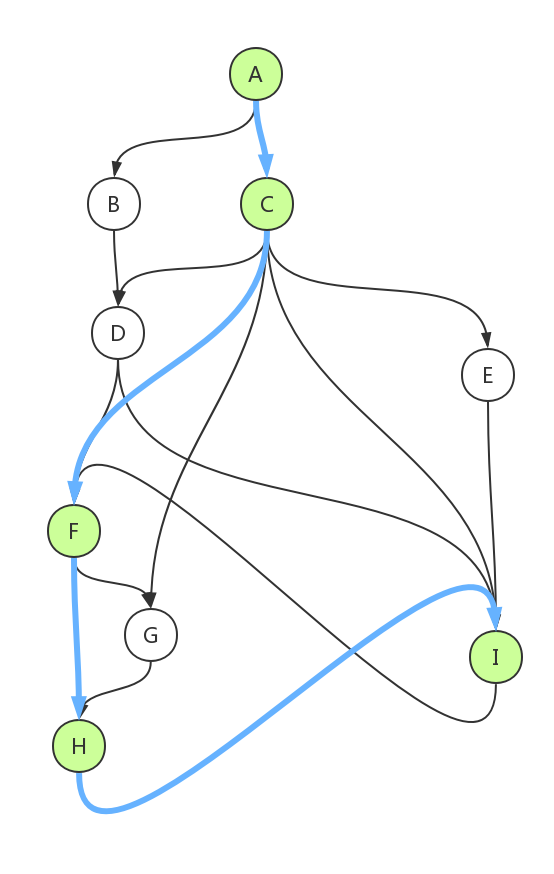
不知道你有没有这种感觉,面对表现不佳的漏斗,只能干着急而不知道从何下手。因为漏斗本身就不太具备可操作性(Actionable),毕竟节点是你选的,除非你承认自己选错了。而行为路径和归因则给漏斗模型补上了可操作性。
所以真的有很多模型要学么?我没觉得。
这个话题我们放在下一篇,嘿嘿……
本文为@运营喵原创,运营喵专栏作者。



{kind=link}